- Pondhouse Data OG - We know data & AI
- Posts
- Pondhouse Data AI - Tips & Tutorials for Data & AI 15
Pondhouse Data AI - Tips & Tutorials for Data & AI 15
Context-Preserved Chunking | Hugging Face Observers for AI Transparency | Enterprise Data Integration with Antrhopics MCP
Andreas Nigg
03 Dec

Hey there,
Welcome to our Pondhouse Data newsletter about all Data & AI.
This week, we're diving into advanced document processing techniques, introducing a new tool for AI observability, and exploring innovative developments in AI reasoning models.
Let’s get started!
Cheers, Andreas & Sascha
In todays edition:
Tutorial: Implementing Late Chunking for Better Context Preservation
Educational Tip: Exploring the “Awesome GPT Prompt Engineering” Repository
Engineering Tip: Implementing Hugging Face's Observer for AI Observability
📰 Industry Updates:
Connecting also legacy data sources in enterprise setups with Anthropics Model Context Protocol (MCP).
Boosting models for coding with Meta’s new training method called Reinforcement Learning with Execution Feedback (RLEF) and enhancing reasoning abilities with a new model design shown in Marco-o1.
Find this Newsletter helpful?
Please forward it to your colleagues and friends - it helps us tremendously.
Tutorial of the week
Late Chunking: A Method for Context Preservation in AI Retrieval

Retrieval Augmented Generation (RAG) systems enhance AI applications by combining external knowledge with language models. A key challenge in RAG is determining the optimal size for document chunks: chunks that are too small may lose important context, while overly large chunks can dilute semantic precision. Late chunking addresses this by processing entire documents through long-context embedding models before dividing them into smaller pieces, preserving both context and semantic accuracy.
Understanding Late Chunking
Traditional chunking methods split documents into fixed-size segments before embedding, which can disrupt the flow of information as each chunk has no information about the overall context of the document.
Late chunking, however, involves embedding the full document first and then dividing it, ensuring that the embeddings of each chunk capture the document's complete context.
If we have for example the following 2 chunks in a document:
chunk1 = "TensorFlow is the most popular framework..."
chunk2 = "It was originally developed..."Traditional (naive) chunking doesn’t have the full context of the document and therefore can’t reall relate “It” in chunk2 to “TensorFlow” in chunk1, but when using late chunking it can attend it to the content of the other chunks through the self-attention mechanism. We can see this clearly when looking at the cosine similarities for the search term “TensorFlow” for both chunking methods.

Benefits of Late Chunking
Enhanced Context Preservation: By embedding the whole document first, the model retains a comprehensive understanding, leading to more accurate information retrieval.
Improved Retrieval Accuracy: Chunks derived from a fully embedded document are more likely to align with user queries, enhancing the relevance of retrieved information.
Implementing Late Chunking
Process the Full Document: Use a long-context embedding model to generate an embedding for the entire document.
Divide the Document: After embedding, split the document into smaller chunks at natural breakpoints, such as paragraphs or sections.
Assign Embeddings to Chunks: Each chunk inherits the embedding of the full document, maintaining the contextual integrity.
For a detailed guide on implementing late chunking, refer to our full article and step-by-step guide below:

Tool of the week
“Awesome GPT Prompt Engineering”

This week's tool isn't a traditional tool but a comprehensive collection of resources on prompt engineering. The Awesome GPT Prompt Engineering repository offers a curated list of guides, techniques, and tools to help you create effective prompts for GPT models.
What's Inside:
Guides and Tutorials: Step-by-step instructions on crafting prompts for various tasks.
Techniques: Methods like few-shot learning and chain-of-thought prompting to enhance model responses.
Prompt Collections: Examples and templates for different applications.
Research Papers: Studies on prompt engineering and its impact on AI models.
Community Links: Access to forums and groups focused on prompt engineering.
Whether you're new to prompt engineering or looking to improve your skills, this repository is a valuable resource.
Top News
Anthropic's Model Context Protocol (MCP)

Anthropic has introduced the Model Context Protocol (MCP), an open standard designed to connect AI assistants like Claude to various data sources, including content repositories, business tools, and development environments. This initiative aims to enhance AI performance by providing seamless access to relevant information.
Purpose and Functionality
AI systems often face challenges accessing diverse datasets due to fragmented integrations and legacy systems. MCP addresses this by offering a universal protocol that enables secure, two-way connections between AI applications and data sources. Developers can expose their data through MCP servers or build AI applications (MCP clients) that connect to these servers, streamlining the integration process.
Key Components
Anthropic has released several resources to support MCP adoption:
MCP Specification and SDKs: Detailed guidelines and software development kits to assist developers in implementing MCP.
Claude Desktop Integration: Local MCP server support within the Claude Desktop app, facilitating direct connections to local datasets.
Open-Source MCP Servers: A repository of pre-built MCP servers for popular systems like Google Drive, Slack, and GitHub, enabling quick integration.
Benefits
By adopting MCP, developers can reduce the need for custom connectors for each data source. This standardization allows AI systems to maintain context as they interact with various tools and datasets, leading to more efficient and scalable AI solutions.
Early adopters, including companies like Block and Apollo, have integrated MCP into their systems, enhancing their AI capabilities. As the ecosystem grows, MCP is poised to become a cornerstone in the development of context-aware AI applications.
Also in the news
Enhancing Code Generation with Execution Feedback

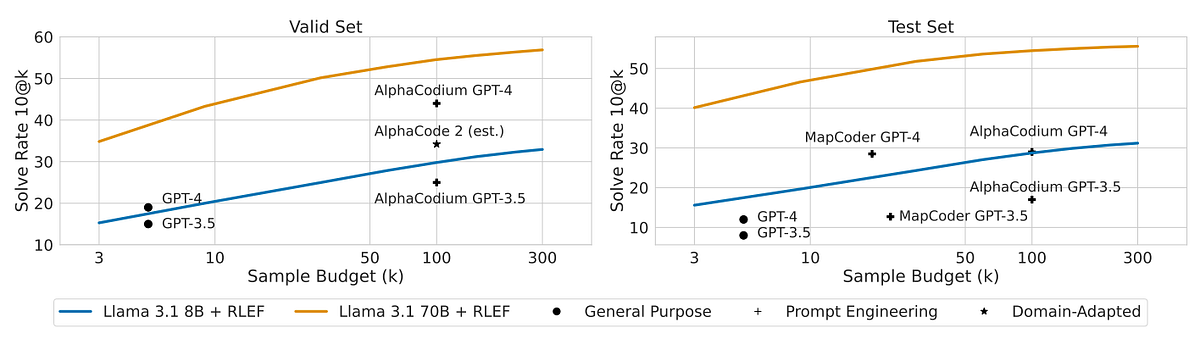
Researchers at Meta have introduced a method to improve code generation by large language models (LLMs) through execution feedback and reinforcement learning. This approach enables models to refine their outputs based on real-time test results, leading to more accurate and reliable code synthesis.
Key Features:
Execution Feedback: Models run generated code against test cases, using the outcomes to inform subsequent iterations.
Reinforcement Learning: Incorporating techniques like Proximal Policy Optimization (PPO), models learn to adjust their code generation strategies to maximize success rates.
Methodology:
Iterative Code Generation: The model generates code solutions in multiple steps. After each attempt, it receives feedback from test case results, which is incorporated into the next iteration.
Public and Private Test Sets: The process uses two sets of test cases. Public tests provide immediate feedback during training, while private tests evaluate the final solution's correctness without influencing the model during training.
Policy Optimization: The model is fine-tuned using Proximal Policy Optimization (PPO), a reinforcement learning technique, to improve its ability to generate correct code over successive attempts.
Benefits:
Iterative Improvement: Models can autonomously refine code outputs, reducing reliance on human intervention.
Enhanced Accuracy: By learning from execution outcomes, models produce more reliable and functional code.
For a comprehensive understanding, refer to the scientific paper detailing this method. Additionally, the Medium article below offers an accessible overview of the approach.
This advancement represents a significant step toward more autonomous and efficient AI-driven code generation, with potential applications across various programming and software development tasks.
Marco-o1: A New Model Design Elevating AI's Reasoning Capabilities
The paper "Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions" introduces Marco-o1, a model designed to enhance reasoning in both structured and open-ended tasks. Inspired by OpenAI's o1 model, Marco-o1 employs several techniques to improve problem-solving across various domains.
Key Components of Marco-o1:
Chain-of-Thought (CoT) Fine-Tuning: This method trains the model to generate step-by-step reasoning, enhancing its ability to tackle complex problems.
Monte Carlo Tree Search (MCTS): MCTS allows the model to explore multiple reasoning paths, using confidence scores to guide the search toward optimal solutions.
Reflection Mechanisms: These enable the model to assess and refine its reasoning processes, leading to more accurate outcomes.
Performance Highlights:
Multilingual Reasoning: Marco-o1 achieved accuracy improvements of 6.17% on the MGSM (English) dataset and 5.60% on the MGSM (Chinese) dataset, indicating enhanced reasoning capabilities in multiple languages.
Colloquial Translation: The model effectively translates slang expressions, demonstrating a strong grasp of colloquial nuances. For example, it accurately translated a Chinese expression meaning "This shoe offers a stepping-on-poop sensation" to the English "This shoe has a comfortable sole."
Marco-o1 represents a significant advancement in developing AI systems capable of handling complex, real-world tasks that require nuanced reasoning and understanding.

Tip of the week
Hugging Face “Observers”
In AI development, understanding and monitoring model interactions are crucial for transparency and performance optimization. This necessity has led to the emergence of monitoring tools like LangSmith and LangFuse. Now, Hugging Face offers Observers, an open-source Python SDK designed to provide comprehensive observability for generative AI APIs.
Why Observability Matters
As AI systems become more complex, tracking their behavior ensures reliability and ethical compliance. Effective observability allows developers to monitor AI interactions, identify issues, and refine models accordingly.
What Observers Offers
Flexible Integration: Observers can wrap any OpenAI-compatible language model provider, facilitating seamless tracking across various AI interactions.
Versatile Storage: The SDK supports multiple backends for storing interaction data, including Hugging Face Datasets, DuckDB, and Argilla, offering flexibility in data management.
User-Friendly Setup: With minimal configuration, developers can quickly integrate Observers into their workflows, making it suitable for both new and existing AI applications.
Alternative Solutions
LangSmith is a closed-source platform offering observability and analytics for language model applications, while LangFuse is an open-source alternative that can be self-hosted. Observers by Hugging Face stands out by providing a lightweight, flexible, and easy-to-use solution for AI observability.
By incorporating Observers into your AI development process, you can gain deeper insights into model performance, leading to more transparent and accountable AI systems.

We hope you liked our newsletter and you stay tuned for the next edition. If you need help with your AI tasks and implementations - let us know. We are happy to help