- Pondhouse Data OG - We know data & AI
- Posts
- Pondhouse Data AI - Tips & Tutorials for Data & AI 38
Pondhouse Data AI - Tips & Tutorials for Data & AI 38
Google’s Sun-Powered Space Data Center | Kimi K2: Open Source GPT-5 Rival | Agent Lightning: Boost Any Agent | Model Learning Without Forgetting
Andreas Nigg
18 Nov

Hey there,
This week’s edition is packed with breakthroughs and practical insights for AI professionals. We’re spotlighting Google’s Nested Learning, a brain-inspired approach to continual training that’s redefining how models retain knowledge, and diving into Agent Lightning, Microsoft’s universal optimization framework for AI agents. You’ll also find a hands-on tutorial for building enterprise-grade agents using the Microsoft Agent Framework, plus actionable tips for slashing token costs in multi-tool agent workflows with MCP code execution. From open-source advances like Kimi Linear and Kimi K2 Thinking to Google’s solar-powered ML infrastructure in space, there’s plenty to inspire your next project.
Let’s dive in!
Cheers, Andreas & Sascha
In today's edition:
📚 Tutorial of the Week: Enterprise AI agents with Microsoft Agent Framework
🛠️ Tool Spotlight: Agent Lightning: universal agent optimization framework
📰 Top News: Google Nested Learning tackles catastrophic forgetting
💡 Tip: Reduce agent token costs with code execution
Let's get started!
Tutorial of the week
Build Enterprise-Ready AI Agents with Microsoft Agent Framework

Looking to move beyond AI agent prototypes and build robust, production-grade solutions? This hands-on guide from Pondhouse Data dives deep into the Microsoft Agent Framework (MAF), showing you how to create a practical IT helpdesk agent that’s secure, scalable, and enterprise-ready. If you want to bridge the gap between cool demos and real-world business impact, this resource is a must-read.
Comprehensive, Step-by-Step Walkthrough: Learn how to set up your environment, define agent tools, manage state, and orchestrate workflows—complete with code samples in Python (and easily adaptable to C#).
Enterprise-Grade Features: Discover how MAF tackles observability, security, human-in-the-loop governance, and long-running task durability—essentials for any serious business deployment.
Modern Development Experience: Explore the built-in Dev Web UI for debugging, and see how to deploy your agent as a scalable FastAPI service, including Dockerization for production.
Deep Integration with Microsoft Ecosystem: Perfect for teams using Azure, .NET, or Copilot Studio, with first-class support for both Python and C# developers.
Practical Example: Build an IT helpdesk agent that triages requests, checks for outages, and creates support tickets—demonstrating real-world agent design patterns.
This guide is ideal for developers, solution architects, and technical leaders aiming to operationalize AI agents in enterprise environments. Start building reliable, observable, and scalable AI solutions today!

Tool of the week
Agent Lightning — Universal optimization for any AI agent framework
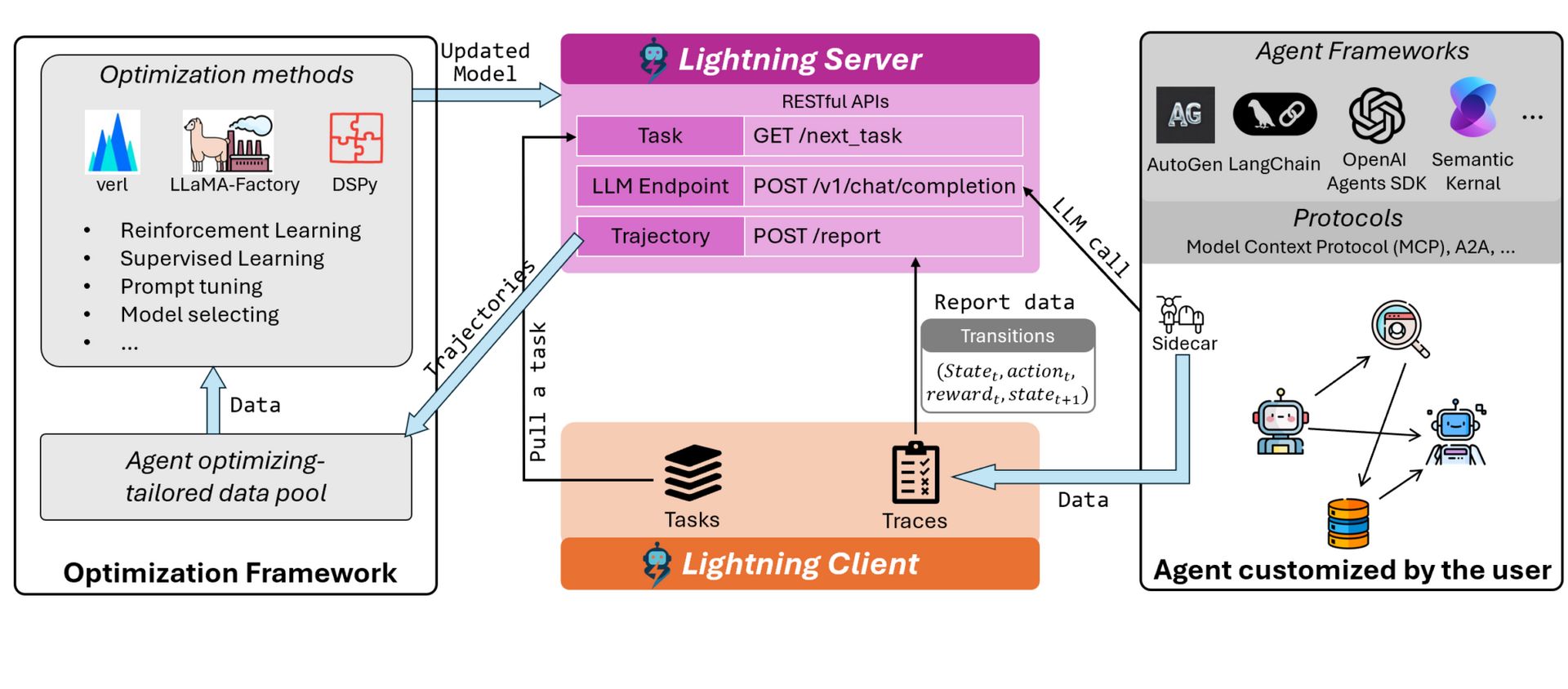
Agent Lightning is a powerful open-source framework from Microsoft that enables seamless optimization of AI agents built with any framework—without requiring code changes. Designed to bridge the gap between agent workflow development and advanced optimization, Agent Lightning empowers teams to move beyond static, pre-trained models and unlock adaptive, learning-based agents in real-world applications.
Framework-agnostic optimization: Works with any agent framework (LangChain, OpenAI Agent SDK, AutoGen, CrewAI, and more), or even vanilla Python agents, allowing you to optimize existing systems without rewrites.
Plug-and-play reinforcement learning: Integrates reinforcement learning (RL), prompt optimization, and supervised fine-tuning directly into agent workflows, supporting complex, multi-turn, and multi-agent scenarios.
Zero code change required: Thanks to its sidecar-based design, Agent Lightning can collect traces, monitor errors, and optimize agent behavior with minimal intrusion—just drop in a helper or use the tracer.
Robust error monitoring: Built-in agent-side error tracking and detailed reporting help maintain stability and accelerate debugging during optimization cycles.
Scalable and extensible: Supports selective optimization in multi-agent systems, and is actively expanding to include more RL algorithms, richer feedback mechanisms, and broader framework compatibility.
With over 8,100 GitHub stars and growing adoption in both research and production settings, Agent Lightning is quickly becoming the go-to solution for anyone looking to train, adapt, and deploy high-performing AI agents at scale.

Top News of the week
Google Introduces Nested Learning: A Brain-Inspired Breakthrough for Continual AI Training

Google Research has unveiled Nested Learning, a novel machine learning paradigm inspired by the human brain’s ability to continually learn without forgetting past knowledge. This approach directly tackles the persistent problem of “catastrophic forgetting” in deep learning models, where learning new tasks often erases proficiency in previously learned ones. By structuring models as collections of smaller, nested learners—each with its own optimization loop and memory system—Nested Learning enables more robust, flexible, and long-lasting AI capabilities.
The proof-of-concept model, Hope, demonstrates the power of this paradigm. Unlike traditional architectures, Hope leverages a continuum memory system (CMS) that updates at multiple time scales, mirroring neuroplasticity in the brain. Experimental results show that Hope outperforms state-of-the-art transformers and recurrent models on language modeling, long-context reasoning, and continual learning tasks. The Nested Learning framework also unifies model architecture and optimization, allowing for deeper computational depth and self-modifying capabilities.

This innovation opens new avenues for building AI systems that learn more like humans, with improved memory retention and adaptability. Developers and researchers can experiment with Nested Learning concepts using PyTorch or JAX, potentially accelerating the next generation of self-improving AI.

Also in the news
Google Project Suncatcher: Solar-Powered ML Training in Space
Google has announced Project Suncatcher, an ambitious initiative to build a solar-powered data center in space for machine learning training. By deploying satellites equipped with advanced solar arrays, Project Suncatcher aims to harness abundant solar energy and dramatically reduce the carbon footprint of large-scale ML workloads. The project explores new approaches to energy-efficient, off-planet data infrastructure, with the goal of enabling sustainable and scalable AI development beyond Earth.
Moonshot AI Unveils Kimi K2 Thinking: Enhanced Reasoning for LLMs
Moonshot AI has introduced Kimi K2 Thinking, a new framework designed to improve the reasoning capabilities of large language models. K2 Thinking enables models to break down complex tasks into multi-step processes, enhancing logical consistency and problem-solving accuracy. In recent benchmarks, Kimi K2 Thinking outperformed GPT-5 and Sonnet 4.5 on mathematical reasoning and multi-hop question answering, achieving up to 8% higher accuracy on GSM8K and 7% better performance on MATH datasets. These results position Kimi K2 as a promising approach for next-generation LLMs.
Google Unveils Supervised Reinforcement Learning for Small LLMs
Google Cloud AI Research has introduced Supervised Reinforcement Learning (SRL), a novel training framework that enables small language models (as small as 7B parameters) to perform structured, step-wise reasoning. Unlike traditional RL approaches that reward only final answers, SRL decomposes reasoning into sequential actions, providing dense feedback at each step. This method significantly improves performance on complex math and software engineering benchmarks, allowing smaller models to generalize reasoning skills previously limited to much larger LLMs.
Moonshot AI Launches Kimi Linear: Fast, Open-Source Linear Attention Model
Moonshot AI has released Kimi Linear, an open-source model featuring a hybrid linear attention architecture designed for high efficiency and scalability. Kimi Linear leverages Kimi Delta Attention (KDA) to achieve up to 6× faster decoding on long-context tasks, supporting sequences up to 1 million tokens. The model reduces memory usage by up to 75% compared to full attention methods, making it especially valuable for large-scale language modeling and reinforcement learning applications. Both base and instruct checkpoints are available for research and deployment.
Cursor Boosts Code Retrieval with Semantic Search Integration
Cursor has enhanced its coding agents with a new semantic search feature, resulting in a 12.5% average accuracy gain in code retrieval tasks. By training a custom embedding model on real agent search traces, Cursor’s semantic search enables more precise and context-aware codebase queries compared to traditional grep-based methods. The improvement leads to better code retention, fewer dissatisfied user requests, and higher productivity for developers working with large repositories.
Tip of the week
Slash Token Costs in AI Agents with Code Execution and MCP
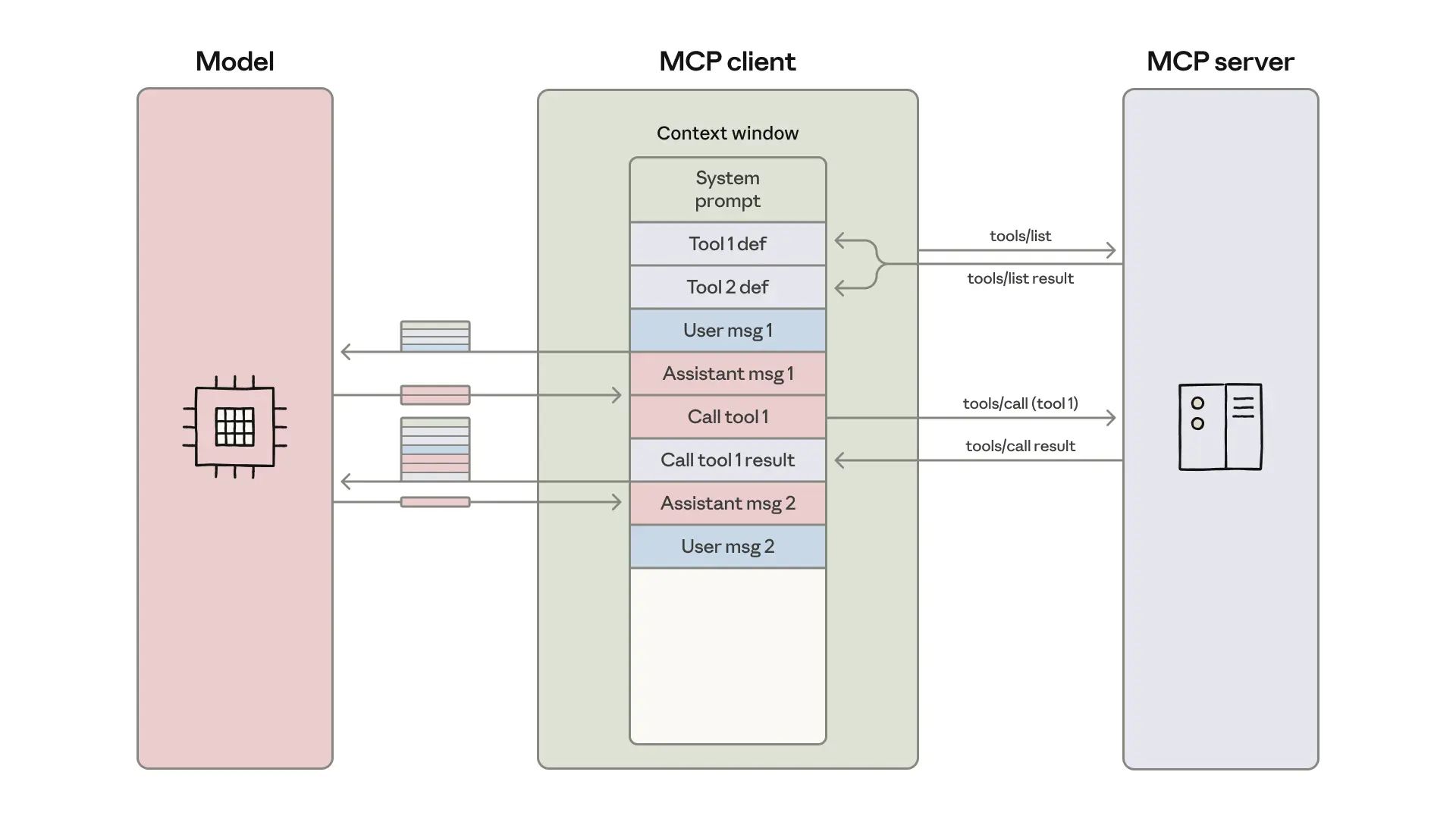
Are your AI agents struggling with ballooning token usage and slowdowns when connecting to many tools? This is a common challenge—especially when agents are wired up to hundreds of tools directly or via an MCP (Model Context Protocol) Server. The core issue: every tool definition and intermediate result sent through the model context increases token counts, making agents slower, more expensive, and less scalable.
What’s the tip?
Instead of loading all tool definitions and passing every piece of data through the model, leverage a code execution environment that lets agents call MCP tools as code modules. This approach keeps only the essential tool definitions and filtered results inside the model context, drastically reducing token consumption.
When is this useful?
When your agent connects to a large number of tools (dozens or hundreds), either directly or via an MCP Server.
When processing large datasets from external sources, where sending all raw data through the model would be inefficient.
When you want to minimize costs and latency, or need to keep sensitive data out of the model’s context for privacy reasons.
How to apply:
Organize MCP tool integrations as code files or modules.
Design your agent to discover and load only the tools required for each specific task, rather than loading everything up front.
Use code to filter, aggregate, or summarize large datasets before returning concise results to the model—only what’s necessary for the next step.
Why it’s useful:
Cuts context overhead by up to 98.7%—making agents faster, cheaper, and more scalable.
Improves privacy by keeping sensitive or unnecessary data out of the model’s context.
Enables more complex workflows and logic using familiar programming constructs, without overwhelming the model with irrelevant information.
If you’re building agents that need to connect to many tools or process large datasets, this approach can make a dramatic difference in efficiency and cost.
We hope you liked our newsletter and you stay tuned for the next edition. If you need help with your AI tasks and implementations - let us know. We are happy to help