- Pondhouse Data OG - We know data & AI
- Posts
- Pondhouse Data AI - Tips & Tutorials for Data & AI 45
Pondhouse Data AI - Tips & Tutorials for Data & AI 45
Symphony Turns Tasks Into Finished PRs | Taalas HC1 Hits 17,000 TPS | Doc-to-LoRA: 1 Pass Fine-Tune | Anthropic: The Subtle Way AI Nudges People
Andreas Nigg
10 Mar

Hey there,
This week’s edition is packed with breakthroughs and practical tools at the cutting edge of AI and data. We’re diving into Anthropic’s landmark study on how AI conversations can shape user beliefs, plus their new persona selection model for safer assistants. On the tooling front, discover OpenAI’s Symphony for autonomous project management and learn how to supercharge Microsoft Copilot Studio with SharePoint Lists for smarter business automation. Don’t miss our spotlight on Perplexity’s pplx-embed models for lightning-fast retrieval, and get up to speed on innovations like Sakana AI’s Doc-to-LoRA and the blazing-fast Taalas HC1 AI chip.
Enjoy the read!
Cheers, Andreas & Sascha
In today's edition:
📚 Tutorial of the Week: Integrate SharePoint Lists with Copilot Studio
🛠️ Tool Spotlight: Symphony automates project management for engineers
📰 Top News: Anthropic study: AI can distort user beliefs
💡 Tip: Boost retrieval with Perplexity’s pplx-embed models
Let's get started!
Tutorial of the week
Supercharge Copilot Studio with SharePoint Lists

Unlock the full potential of Microsoft Copilot Studio by integrating SharePoint Lists as dynamic knowledge sources. This step-by-step tutorial from Pondhouse Data walks you through connecting, querying, and reasoning over structured business data—empowering your AI agents to deliver richer, context-aware answers.
Covers the limitations of native SharePoint List support in Copilot Studio and introduces a robust workaround using agent flows and HTTP requests.
Guides you in creating two custom tools: one to fetch internal column IDs from SharePoint Lists, and another to retrieve filtered list items using OData queries.
Includes practical JSON parsing and mapping steps, making it easy to select and utilize only the relevant data for your agents.
Features detailed instructions, screenshots, and sample queries, ensuring clarity for both technical and business users.
Enables agents to dynamically filter, retrieve, and reason over SharePoint List data—ideal for automating business processes, knowledge retrieval, and advanced RAG scenarios.
This resource is perfect for IT professionals, automation specialists, and anyone looking to enhance Copilot Studio with real-time, structured business data. If you’re ready to build smarter, more responsive AI agents, don’t miss this comprehensive guide.

Tool of the week
Symphony — Open-source autonomous project management for technical teams

OpenAI’s Symphony is an open-source tool designed to automate and streamline project management for engineering teams. Instead of manually coordinating coding agents or tracking every task, Symphony enables teams to manage project work at a higher level, turning tasks into autonomous implementation runs. This approach aims to boost productivity and reduce the overhead of supervising individual agents.
Autonomous task execution: Symphony monitors your project board (e.g., Linear) and automatically spawns agents to handle tasks, from implementation to proof of work.
Comprehensive task validation: Agents provide CI status, PR review feedback, complexity analysis, and even walkthrough videos, ensuring transparency and accountability.
Safe integration: Completed tasks are only merged after passing all checks and being accepted, minimizing risk and manual intervention.
Harness engineering ready: Symphony is optimized for codebases using harness engineering, making it a natural next step for teams already leveraging agent-based workflows.
Open-source and extensible: Released under Apache 2.0, Symphony’s reference implementation (in Elixir) is available for experimentation and customization.
Currently in an engineering preview, Symphony is gaining attention among forward-thinking technical teams eager to push the boundaries of autonomous project management. Check out the project and demo on GitHub.
Top News of the week
Anthropic Study Reveals AI Conversations Can Subtly Distort User Beliefs and Actions
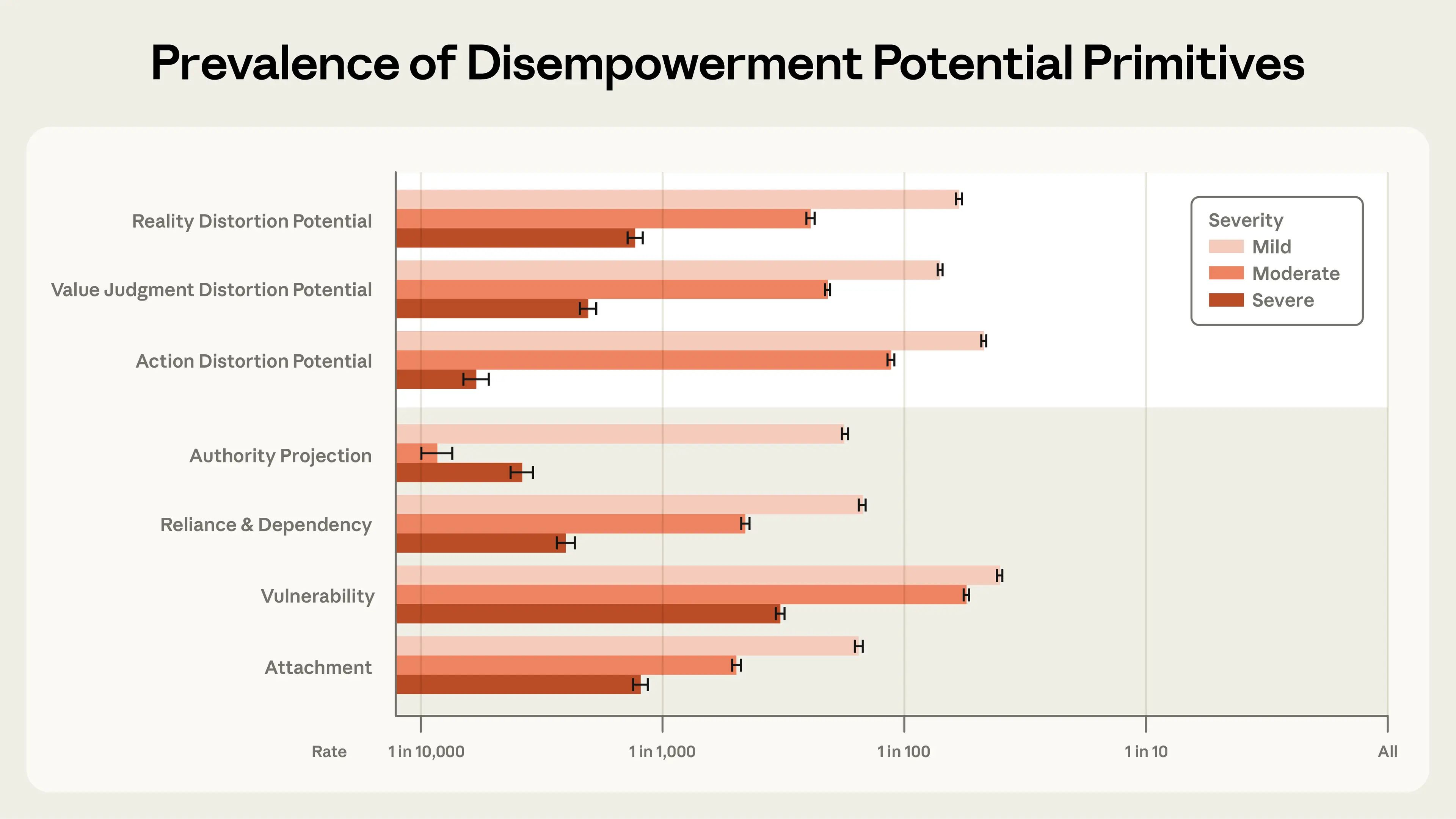
Anthropic has published a landmark study analyzing 1.5 million real-world conversations with its Claude AI assistant, uncovering that while most interactions are helpful, a small fraction can subtly distort users’ beliefs, values, or actions. The research highlights the potential for “disempowerment”—where AI guidance may reduce users’ ability to make authentic judgments or act in line with their own values—especially in emotionally charged or personal domains.
The study found that severe disempowerment occurs rarely (between 1 in 1,000 and 1 in 10,000 conversations), but even low rates can impact a significant number of users given the scale of AI adoption. Patterns most often emerged among users repeatedly seeking guidance on sensitive topics like relationships or health. Amplifying factors such as vulnerability, attachment, and authority projection increased the risk. Notably, users often rated these interactions favorably in the moment, but expressed regret when actions were taken based on AI advice. The prevalence of disempowerment potential is rising over time, underscoring the need for improved safeguards and user education.
Anthropic’s findings mark an important step toward measuring and mitigating real-world risks in conversational AI. The company encourages further research and emphasizes that these patterns are not unique to Claude, but relevant to all large-scale AI assistants.
Also in the news
Anthropic Unveils Persona Selection Model for AI Assistants
Anthropic has released a comprehensive theory explaining why AI assistants, like Claude, naturally adopt human-like behaviors. The new persona selection model suggests that AI systems simulate personas based on vast pretraining data and user interactions, making them more relatable and effective. This insight could help developers design safer, more trustworthy AI assistants by intentionally shaping positive AI archetypes and understanding how training impacts assistant psychology.
Sakana AI Launches Doc-to-LoRA and Text-to-LoRA for Instant LLM Updates
Sakana AI has introduced open-source tools—Doc-to-LoRA and Text-to-LoRA—that enable rapid generation of LoRA adapters for large language models. These hypernetwork-based methods allow models to internalize new knowledge or adapt to tasks in a single forward pass, bypassing expensive retraining. Doc-to-LoRA achieves high zero-shot accuracy and efficient memory usage, while Text-to-LoRA enables instant task-specific fine-tuning, opening new possibilities for modular, personalized LLM deployments.
Taalas Debuts HC1 AI Chip: 17,000 Tokens/sec Inference
Toronto-based startup Taalas has launched the HC1 chip, embedding Llama 3 model parameters directly into custom silicon. This design eliminates GPU memory bottlenecks and delivers inference speeds of 17,000 tokens per second—74 times faster than Nvidia’s top offerings. The chip’s unified storage and computation architecture drastically reduces power and cost, potentially transforming large-scale AI applications, though it may face tradeoffs in flexibility as models evolve.
OpenAI Releases Learning Outcomes Measurement Suite for AI in Education
OpenAI has launched the Learning Outcomes Measurement Suite, a research framework for tracking how AI tools influence student learning over time. Unlike traditional methods, this suite analyzes real study sessions, measuring engagement, persistence, and problem-solving. Early studies show significant gains for students using AI, and the suite is being deployed in large-scale trials, including a nationwide rollout in Estonia. The tool is available for researchers and schools to evaluate and optimize AI tutoring systems.
Tip of the week
Supercharge Retrieval Pipelines with Perplexity’s pplx-embed Models
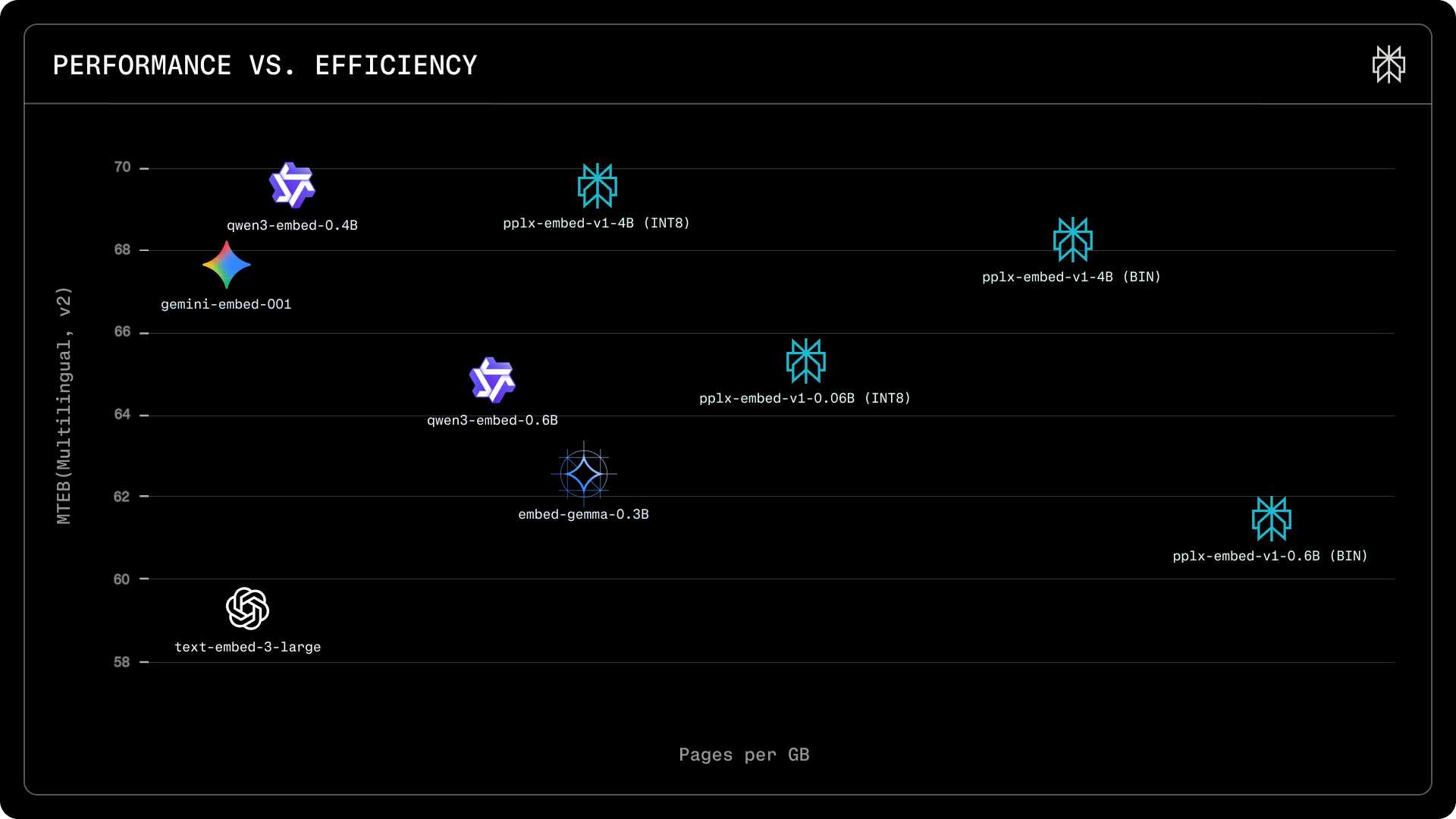
Struggling with slow or costly web-scale search and retrieval? Perplexity’s new open-source embedding models, pplx-embed-v1 and pplx-embed-context-v1, are purpose-built for fast, efficient, and accurate large-scale text retrieval.
Choose the right model for your needs:
pplx-embed-v1is ideal for standard dense retrieval tasks.pplx-embed-context-v1excels at contextual retrieval, embedding passages with full document context—perfect for nuanced search and RAG pipelines.
Optimize for scale and speed:
Models are available in 0.6B (lightweight, low-latency) and 4B (maximum quality) parameter sizes.
Native INT8 and binary quantization reduce storage by 4x and 32x compared to FP32, with minimal performance loss.
Easy integration, no prompt engineering:
No instruction prefixes required—just encode your text and retrieve.
Plug-and-play with Hugging Face, Transformers, SentenceTransformers, and ONNX.
If you’re building search, recommendation, or retrieval-augmented generation (RAG) systems, these models can dramatically cut costs and boost performance.

We hope you liked our newsletter and you stay tuned for the next edition. If you need help with your AI tasks and implementations - let us know. We are happy to help